Bug 97546
| Summary: | Memory grows up | ||||||
|---|---|---|---|---|---|---|---|
| Product: | [Retired] Red Hat Linux | Reporter: | Pierre-Yves Antunez <pierre-yves.antunez> | ||||
| Component: | kernel | Assignee: | Dave Jones <davej> | ||||
| Status: | CLOSED WONTFIX | QA Contact: | Brian Brock <bbrock> | ||||
| Severity: | high | Docs Contact: | |||||
| Priority: | medium | ||||||
| Version: | 9 | CC: | dag, k.georgiou, marino.simons, mattdm, pfrields, pknirsch, redhat-bug | ||||
| Target Milestone: | --- | ||||||
| Target Release: | --- | ||||||
| Hardware: | i686 | ||||||
| OS: | Linux | ||||||
| Whiteboard: | |||||||
| Fixed In Version: | Doc Type: | Bug Fix | |||||
| Doc Text: | Story Points: | --- | |||||
| Clone Of: | Environment: | ||||||
| Last Closed: | 2004-09-30 15:41:09 UTC | Type: | --- | ||||
| Regression: | --- | Mount Type: | --- | ||||
| Documentation: | --- | CRM: | |||||
| Verified Versions: | Category: | --- | |||||
| oVirt Team: | --- | RHEL 7.3 requirements from Atomic Host: | |||||
| Cloudforms Team: | --- | Target Upstream Version: | |||||
| Embargoed: | |||||||
| Attachments: |
|
||||||
if it really is a kernel memory leak (and not some userland application eating all of memory) it would be important to know exactly which drivers you are using. Also, could you please show us your free output at boot, after a few days and when the system is near crashing ? Created attachment 92583 [details]
Free command
Here is the free command after 2 days.
When the number will be 0 the machine crash
In all those cases the system looks completely normal, with no swapping and .5Gb of swap free. The memory is filling with cache which looks fine I cant't understand why the number of memory buffer are less day after day Subject: Kernel memory leak in 2.4.20
I have a similar problem with my 64MB i586 firewall. It eats about 5MB every
night at 22h when a heavy cronjob ends (rrdtool graphing). After 2 weeks the
machine is out of memory, nothing left for buffers and cache and starts trashing
heavily. A reboot is the only useful thing to do ;-(
It is a almost clean RH9 with a vanilla 2.4.20-* RH kernel.
I have a graph at:
http://dag.wieers.com/rmon-breeg-mem-3months-800x120.png
No process is claiming this memory. When the system boots it uses about 15MB RAM
(httpd, dhcp, named, vtun, ntpd, smb)
A friend of mine has the same problem on a machine that does mrtg graphing.
Every 3 days this machine trashes and needs a on-site reboot. Memory disappears.
Also a RH9.
The following information may be useful:
[root@breeg breeg]# cat endpoint_kernel
1054071629 2.4.20-8
1054772101 2.4.20-18.9
1059907801 2.4.20-19.9
[root@breeg breeg]# cat endpoint_boottime
1054071629 Tue May 27 23:08:40 2003
1054147201 Wed May 28 20:33:15 2003
1054772101 Thu Jun 5 02:13:31 2003
1055079001 Sun Jun 8 15:25:07 2003
1056320401 Mon Jun 23 00:17:35 2003
1057525501 Sun Jul 6 23:01:21 2003
1058556001 Fri Jul 18 21:17:58 2003
1059550501 Wed Jul 30 09:32:47 2003
1059907801 Sun Aug 3 12:43:48 2003
[root@breeg breeg]# lsmod
Module Size Used by Not tainted
nls_iso8859-1 3484 0 (autoclean)
nls_cp437 5116 0 (autoclean)
vfat 11948 0 (autoclean)
fat 36792 0 (autoclean) [vfat]
tun 5440 3 (autoclean)
ip_nat_ftp 3888 0 (unused)
ip_conntrack_ftp 5008 1
parport_pc 17508 1 (autoclean)
lp 8580 0 (autoclean)
parport 33952 1 (autoclean) [parport_pc lp]
8139too 17000 3
mii 3720 0 [8139too]
ipt_REJECT 3736 1 (autoclean)
ipt_LOG 4120 3 (autoclean)
ipt_state 1048 3 (autoclean)
ipt_MASQUERADE 2072 3 (autoclean)
iptable_nat 20568 2 (autoclean) [ip_nat_ftp ipt_MASQUERADE]
ip_conntrack 26088 3 (autoclean) [ip_nat_ftp ip_conntrack_ftp
ipt_state ipt_MASQUERADE iptable_nat]
iptable_filter 2316 1 (autoclean)
ip_tables 14488 8 [ipt_REJECT ipt_LOG ipt_state ipt_MASQUERADE
iptable_nat iptable_filter]
ext3 64704 3
jbd 47860 3 [ext3]
[root@breeg breeg]# cat /proc/meminfo
total: used: free: shared: buffers: cached:
Mem: 63156224 61960192 1196032 0 1273856 11702272
Swap: 468824064 10022912 458801152
MemTotal: 61676 kB
MemFree: 1168 kB
MemShared: 0 kB
Buffers: 1244 kB
Cached: 9292 kB
SwapCached: 2136 kB
Active: 8680 kB
ActiveAnon: 4216 kB
ActiveCache: 4464 kB
Inact_dirty: 0 kB
Inact_laundry: 3376 kB
Inact_clean: 724 kB
Inact_target: 2556 kB
HighTotal: 0 kB
HighFree: 0 kB
LowTotal: 61676 kB
LowFree: 1168 kB
SwapTotal: 457836 kB
SwapFree: 448048 kB
Any help would be appreciated. I cannot find information on how many memory the
kernel allocates, I can only see it not being claimed by any process and
'disappear'.
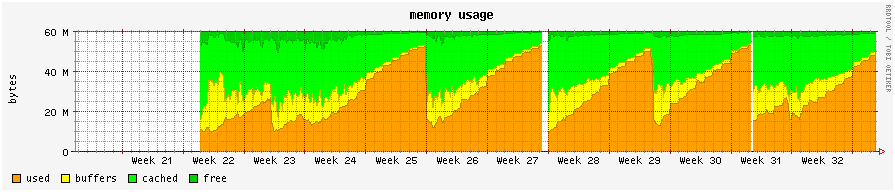
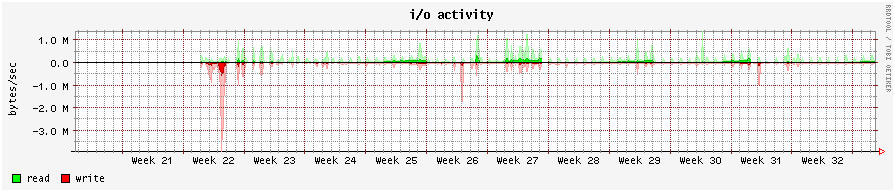
Hmmm, reading back I noticed that the original report isn't a real kernel memory leak. Should I create a new bugreport ? Since this was assigned and not closed I thought it was a valid report. BT The machine is almost exploding, so in case you need more info before it explodes, now is a good time. (Or every 2 weeks) OK, I figured this may be of interest too:
http://dag.wieers.com/rmon-breeg-io-3months-800x120.png
http://dag.wieers.com/rmon-breeg-kernel-3months-800x120.png
http://dag.wieers.com/rmon-breeg-load-3months-800x120.png
http://dag.wieers.com/rmon-breeg-paging-3months-800x120.png
http://dag.wieers.com/rmon-breeg-swap-3months-800x120.png
http://dag.wieers.com/rmon-breeg-mem-3months-800x120.png
Since it isn't using any swap and isn't paging it may indicate that it really is
a kernel memory leak. Although I still don't know where I can see how much
memory the kernel is using and for what.
We have similiar problems on three Machines 2 with hpt37x2 raid controller, one
without.
All run redhat-kernel 2.4.20-8 on Athlons and Pentium.
Free after 4 Days
total used free shared buffers cached
Mem: 513848 507332 6516 0 102128 137928
-/+ buffers/cache: 267276 246572
Swap: 1004020 3424 1000596
load is constantly round about 1, with idle 100% and iowait of 0%
Head of top:
13:43:09 up 4 days, 1:12, 1 user, load average: 1,00, 1,03, 1,01
59 processes: 56 sleeping, 3 running, 0 zombie, 0 stopped
CPU states: 0,0% user 0,0% system 0,0% nice 0,0% iowait 100,0% idle
Mem: 513848k av, 507080k used, 6768k free, 0k shrd, 101120k buff
195864k actv, 0k in_d, 10652k in_c
Swap: 1004020k av, 3460k used, 1000560k free 138404k cached
First, 2.4.20-18.9 is a little old now, and there are VM fixes in 20-20. Secondly, when the machine is in a bad state, take a look at /proc/slabinfo which will tell you what the kernel has done with its allocations. I've been able to reproduce this or a very similar bug here locally: Copying millions of files over NFS to the locale drive eats up all memory after a while, no matter if you have swap enabled or not. Looking at /proc/slabinfo reveals that the inode_cache doesn't get cleanup up anymore when memory gets tight. I'm testing this on the current Taroon kernel which seems to show the same symptoms. Read ya, Phil I test with the 2.4.20-20 and the problem is still the same. I recompile a kernel in 2.4.18 and the problem disapears. OK, i've done some thorough testing here with the latest Taroon bits and can narrow it down to the following problem (and which makes me pretty sure it's actually a new bug): When copying from a NFS server to the local machine the kernel doesn't free the inode_cache entries allocated for the files on the NFS filesystem. The local ones get reclaimed after a short while, but to free the NFS inode_cache entries the NFS filesystem needs to be unmounted. I've verified this on 2 separate machines, it's 100% reproducible and if a huge number of files get copied from the NFS volume the machine will end up dead in the water with 80% kswapd. Read ya, Phil I've also reported the problem on the rhl-devel-list, you can find
the thread at:
Kernel eating memory, ends up trashing
http://www.redhat.com/archives/rhl-devel-list/2003-September/msg00032.html
I have the same problem. Tried with different machines, and different kernels: 2.4-18 crashes on 256mb machine after 7!!! hours. I've built a cystom 2.4.20- 20.9 kernel and with this on 512mb machine, it runs for about 24 hours. To make the problem more difficult, I do have 1 machine that runs kernel 2.4.20- 18.8 without any problems (pentium III on an intel BX board). I suspected first my applications (Big brother, mrtg, routermon), but now I suspect the kernel I too have this problem. I just set up a new server last night with
RH9, grabbed all updates, and now running on 2.4.20-20.9. The system
hasnt even been up for 24hrs and I see the following:
> free
total used free shared buffers
cached
Mem: 1547992 1528396 19596 0 146880
1228792
-/+ buffers/cache: 152724 1395268
Swap: 1028112 37760 990352
I am running an AMD 1.3ghz T-Bird with 1.5gb PC133. And when i check
memory usage by process (via webmin) and total up the numbers, I am
only seeing 274mb of ram being used. So it makes me wonder where the
other 1.25gb of ram is.
Greg, that's not a memory leak. You're really only using 152MB. 146MB is used for buffers and everything else is cached or free. Which is pretty normal. Please note that the original bugreport is also not a memory leak. Dag, You say it's not a memory leak ok perhaps but let this machine a few days more in this state and you will see that the runqueue will be over 20 and you need to reboot it. So what is really the problem even it's not a memory problem. If you compile a new kernel on kernel.org you don't have this kind of result. Regards I would open a new bugreport and report what processes are in the runqueue and other useful information. The memory output looks pretty normal to me and there was no indication you had another problem. Thanks for the bug report. However, Red Hat no longer maintains this version of the product. Please upgrade to the latest version and open a new bug if the problem persists. The Fedora Legacy project (http://fedoralegacy.org/) maintains some older releases, and if you believe this bug is interesting to them, please report the problem in the bug tracker at: http://bugzilla.fedora.us/ |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
From Bugzilla Helper: User-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1) Description of problem: After booting , the memory grows up anormally. After 2 ou 3 days, the free memory is about 40M and the machine becomes to swap. The runqueue reach to 20. Finally the machine crash. Version-Release number of selected component (if applicable): kernel 2.4.20-18.9 How reproducible: Always Steps to Reproduce: 1.boot 2.run the free command after the boot 3.run the free command 2 days later Additional info: