Bug 1917537
| Summary: | controllers continuously busy reconciling operator | ||
|---|---|---|---|
| Product: | OpenShift Container Platform | Reporter: | Tereza <tgabriel> |
| Component: | OLM | Assignee: | Haseeb Tariq <htariq> |
| OLM sub component: | OLM | QA Contact: | xzha |
| Status: | CLOSED ERRATA | Docs Contact: | |
| Severity: | urgent | ||
| Priority: | urgent | CC: | abraj, agomezpr, bturner, daharmon, htariq, jayoung, jiazha, krizza, oarribas, pneedle, rpalathi, smaudet, travi, tsmetana, vkochuku |
| Version: | 4.6.z | Keywords: | Reopened, ServiceDeliveryImpact, Triaged |
| Target Milestone: | --- | ||
| Target Release: | 4.7.0 | ||
| Hardware: | Unspecified | ||
| OS: | Unspecified | ||
| Whiteboard: | |||
| Fixed In Version: | Doc Type: | Bug Fix | |
| Doc Text: |
Cause: Previously, the `csv.status.LastUpdateTime` time comparison in the cluster service version (CSV) reconciliation loop always returned a `false` result.
Consequence: This caused the Operator Lifecycle Manager (OLM) Operator to continuously update the CSV object and trigger another reconciliation event.
Fix: The time comparison is now improved.
Result: The CSV is no longer updated when there are no status changes.
|
Story Points: | --- |
| Clone Of: | Environment: | ||
| Last Closed: | 2021-02-24 15:54:15 UTC | Type: | Bug |
| Regression: | --- | Mount Type: | --- |
| Documentation: | --- | CRM: | |
| Verified Versions: | Category: | --- | |
| oVirt Team: | --- | RHEL 7.3 requirements from Atomic Host: | |
| Cloudforms Team: | --- | Target Upstream Version: | |
| Embargoed: | |||
| Bug Depends On: | |||
| Bug Blocks: | 1924257 | ||
I am closing this duplicate bug in favor of reopening original bug with number #1888073. *** This bug has been marked as a duplicate of bug 1888073 *** I can reliably reproduce the OLM operator's controller becoming stuck in a reconcile hot-loop on openshift clusters 4.6.8 and 4.6.13 but not on the latest nightly 4.7.0-0.nightly-2021-01-19. Reopening this since it's not clear if this is a duplicate of https://bugzilla.redhat.com/show_bug.cgi?id=1888073 even if it has the same symptoms of a busy reconcile loop. Given that the problem appears even with the patch fix (https://github.com/operator-framework/operator-lifecycle-manager/pull/1852) it might still be related without being the same issue. Steps to Reproduce: 1. Setup a 4.6.z cluster 2. Install the Openshift Cluster Storage (OCS) operator from operatorhub 3. Inspect the OLM operator pod's cpu usage and logs OLM operator logs: --- time="2021-01-21T20:56:20Z" level=info msg="checking ocs-operator.v4.6.1" 2021-01-21T20:56:20.106Z DEBUG controllers.operator reconciling operator {"request": "/ocs-operator.openshift-storage"} 2021-01-21T20:56:20.106Z DEBUG controller-runtime.controller Successfully Reconciled {"controller": "subscription", "request": "openshift-storage/ocs-operator"} 2021-01-21T20:56:20.139Z DEBUG controller-runtime.controller Successfully Reconciled {"controller": "clusterserviceversion", "request": "openshift-storage/ocs-operator.v4.6.1"} 2021-01-21T20:56:20.190Z DEBUG controller-runtime.controller Successfully Reconciled {"controller": "operator", "request": "/ocs-operator.openshift-storage"} 2021-01-21T20:56:20.190Z DEBUG controllers.operator reconciling operator {"request": "/ocs-operator.openshift-storage"} 2021-01-21T20:56:20.190Z DEBUG controllers.operator Operator is already up-to-date {"request": "/ocs-operator.openshift-storage"} 2021-01-21T20:56:20.190Z DEBUG controller-runtime.controller Successfully Reconciled {"controller": "operator", "request": "/ocs-operator.openshift-storage"} time="2021-01-21T20:56:21Z" level=info msg="csv in operatorgroup" csv=ocs-operator.v4.6.1 id=ZVFRm namespace=openshift-storage opgroup=openshift-storage-xgn44 phase=Succeeded time="2021-01-21T20:56:21Z" level=info msg="checking ocs-operator.v4.6.1" --- Note: https://bugzilla.redhat.com/show_bug.cgi?id=1903034 will reduce the number of DEBUG logs printed but it won't fix the underlying reconciliation loop issue. As we're proceeding with the fix, I'll repeat my steps to reproduce the issue on the latest 4.6.z cluster (4.6.13 for me) so we can verify the patch once it's merged:
1. Install a 4.6.13+ openshift cluster
2. Install either the Red Hat Openshift Cluster Storage (OCS) operator or Advanced Cluster Management (ACM) operator from operatorhub. Both are known to result in the hotloop.
3. Wait for the operator to finish installing i.e CSV has "status.phase: Succeeded" and "status.reason: InstallSucceeded"
4. Observe the OLM operator pod's logs to see the following block (similar for ACM operator) repeating about every second
```
time="2021-01-21T20:56:20Z" level=info msg="checking ocs-operator.v4.6.1"
2021-01-21T20:56:20.106Z DEBUG controllers.operator reconciling operator {"request": "/ocs-operator.openshift-storage"}
2021-01-21T20:56:20.106Z DEBUG controller-runtime.controller Successfully Reconciled {"controller": "subscription", "request": "openshift-storage/ocs-operator"}
2021-01-21T20:56:20.139Z DEBUG controller-runtime.controller Successfully Reconciled {"controller": "clusterserviceversion", "request": "openshift-storage/ocs-operator.v4.6.1"}
2021-01-21T20:56:20.190Z DEBUG controller-runtime.controller Successfully Reconciled {"controller": "operator", "request": "/ocs-operator.openshift-storage"}
2021-01-21T20:56:20.190Z DEBUG controllers.operator reconciling operator {"request": "/ocs-operator.openshift-storage"}
2021-01-21T20:56:20.190Z DEBUG controllers.operator Operator is already up-to-date {"request": "/ocs-operator.openshift-storage"}
2021-01-21T20:56:20.190Z DEBUG controller-runtime.controller Successfully Reconciled {"controller": "operator", "request": "/ocs-operator.openshift-storage"}
time="2021-01-21T20:56:21Z" level=info msg="csv in operatorgroup" csv=ocs-operator.v4.6.1 id=ZVFRm namespace=openshift-storage opgroup=openshift-storage-xgn44 phase=Succeeded
time="2021-01-21T20:56:21Z" level=info msg="checking ocs-operator.v4.6.1"
```
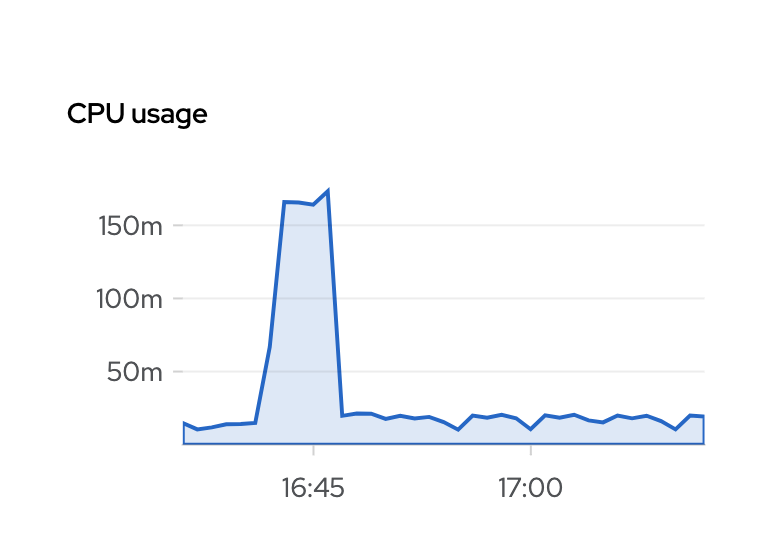
5. Observe the CPU core usage of the OLM operator pod from the console. It should consistently be at a higher than average value, ~170m with the OCS operator and ~847m for the ACM operator.
6. Observe the CSV for the operator which will also be getting updated at a similar frequency:
```
$ oc -n openshift-storage get clusterserviceversions.operators.coreos.com -w
NAME DISPLAY VERSION REPLACES PHASE
ocs-operator.v4.6.2 OpenShift Container Storage 4.6.2 Succeeded
ocs-operator.v4.6.2 OpenShift Container Storage 4.6.2 Succeeded
ocs-operator.v4.6.2 OpenShift Container Storage 4.6.2 Succeeded
ocs-operator.v4.6.2 OpenShift Container Storage 4.6.2 Succeeded
ocs-operator.v4.6.2 OpenShift Container Storage 4.6.2 Succeeded
...
```
With the patch to 4.6.z, the OLM operator pod should not fall into the above reconcile loop for either OCS or ACM operator installs.
You should be able to confirm this by observing the OLM operator logs, the operator CSV, and the pod CPU usage which should now be back to the average i.e < 10m.
For 4.7 this issue is not reproducible and the OLM operator never falls into the above loop with either operator install, so the patch will not have an observable effect.
Plan to verify it by below procedure: 1. Install a 4.7 openshift cluster [root@preserve-olm-env bug1917537]# oc get clusterversion NAME VERSION AVAILABLE PROGRESSING SINCE STATUS version 4.7.0-0.nightly-2021-02-03-063341 True False 18m Cluster version is 4.7.0-0.nightly-2021-02-03-063341 [root@preserve-olm-env bug1917537]# oc adm release info registry.ci.openshift.org/ocp/release:4.7.0-0.nightly-2021-02-03-063341 --commits|grep operator-lifecycle-manager operator-lifecycle-manager https://github.com/operator-framework/operator-lifecycle-manager 0373c9ba7c3dd29fe4b5229cf6df2444e493544b 2. Install Red Hat Openshift Cluster Storage (OCS) operator and Advanced Cluster Management (ACM) operator, Wait for the operator to finish installing [root@preserve-olm-env bug1917537]# oc -n open-cluster-management get csv NAME DISPLAY VERSION REPLACES PHASE advanced-cluster-management.v2.1.2 Advanced Cluster Management for Kubernetes 2.1.2 advanced-cluster-management.v2.1.0 Succeeded [root@preserve-olm-env bug1917537]# oc -n openshift-storage get csv NAME DISPLAY VERSION REPLACES PHASE ocs-operator.v4.6.2 OpenShift Container Storage 4.6.2 Succeeded [root@preserve-olm-env bug1917537]# 3. check the OLM operator pod's logs [root@preserve-olm-env bug1917537]# oc logs --since=410s olm-operator-7d65fc6994-vrpbb | grep -i debug | grep -i "reconciling operator" 2021-02-03T08:18:28.284Z DEBUG controllers.operator reconciling operator {"request": "/advanced-cluster-management.open-cluster-management"} 2021-02-03T08:18:28.442Z DEBUG controllers.operator reconciling operator {"request": "/ocs-operator.openshift-storage"} 2021-02-03T08:18:28.517Z DEBUG controllers.operator reconciling operator {"request": "/advanced-cluster-management.open-cluster-management"} 2021-02-03T08:18:28.521Z DEBUG controllers.operator reconciling operator {"request": "/ocs-operator.openshift-storage"} 2021-02-03T08:18:42.501Z DEBUG controllers.operator reconciling operator {"request": "/advanced-cluster-management.open-cluster-management"} 2021-02-03T08:18:42.592Z DEBUG controllers.operator reconciling operator {"request": "/advanced-cluster-management.open-cluster-management"} 2021-02-03T08:18:42.655Z DEBUG controllers.operator reconciling operator {"request": "/advanced-cluster-management.open-cluster-management"} 2021-02-03T08:18:42.765Z DEBUG controllers.operator reconciling operator {"request": "/advanced-cluster-management.open-cluster-management"} [root@preserve-olm-env bug1917537]# oc logs --since=300s olm-operator-7d65fc6994-vrpbb | grep -i debug | grep -i "reconciling operator" [root@preserve-olm-env bug1917537]# 4. Observe the CPU core usage of the OLM operator pod from the console. The cpu usage is back to normal after the operator installation is finished. 5. check the CSV for the operator [root@preserve-olm-env bug1917537]# oc get ip -n open-cluster-management NAME CSV APPROVAL APPROVED install-rrvl7 advanced-cluster-management.v2.1.2 Automatic true [root@preserve-olm-env bug1917537]# oc -n open-cluster-management get csv NAME DISPLAY VERSION REPLACES PHASE advanced-cluster-management.v2.1.2 Advanced Cluster Management for Kubernetes 2.1.2 advanced-cluster-management.v2.1.0 Succeeded [root@preserve-olm-env bug1917537]# oc get ip -n openshift-storage NAME CSV APPROVAL APPROVED install-fs2dc ocs-operator.v4.6.2 Automatic true [root@preserve-olm-env bug1917537]# oc -n openshift-storage get csv -w NAME DISPLAY VERSION REPLACES PHASE ocs-operator.v4.6.2 OpenShift Container Storage 4.6.2 Succeeded Plan to verify it by below procedure: 1. Install a 4.7 openshift cluster [root@preserve-olm-env bug1917537]# oc get clusterversion NAME VERSION AVAILABLE PROGRESSING SINCE STATUS version 4.7.0-0.nightly-2021-02-03-063341 True False 18m Cluster version is 4.7.0-0.nightly-2021-02-03-063341 [root@preserve-olm-env bug1917537]# oc adm release info registry.ci.openshift.org/ocp/release:4.7.0-0.nightly-2021-02-03-063341 --commits|grep operator-lifecycle-manager operator-lifecycle-manager https://github.com/operator-framework/operator-lifecycle-manager 0373c9ba7c3dd29fe4b5229cf6df2444e493544b 2. Install Red Hat Openshift Cluster Storage (OCS) operator and Advanced Cluster Management (ACM) operator, Wait for the operator to finish installing [root@preserve-olm-env bug1917537]# oc -n open-cluster-management get csv NAME DISPLAY VERSION REPLACES PHASE advanced-cluster-management.v2.1.2 Advanced Cluster Management for Kubernetes 2.1.2 advanced-cluster-management.v2.1.0 Succeeded [root@preserve-olm-env bug1917537]# oc -n openshift-storage get csv NAME DISPLAY VERSION REPLACES PHASE ocs-operator.v4.6.2 OpenShift Container Storage 4.6.2 Succeeded [root@preserve-olm-env bug1917537]# 3. check the OLM operator pod's logs [root@preserve-olm-env bug1917537]# oc logs --since=410s olm-operator-7d65fc6994-vrpbb | grep -i debug | grep -i "reconciling operator" 2021-02-03T08:18:28.284Z DEBUG controllers.operator reconciling operator {"request": "/advanced-cluster-management.open-cluster-management"} 2021-02-03T08:18:28.442Z DEBUG controllers.operator reconciling operator {"request": "/ocs-operator.openshift-storage"} 2021-02-03T08:18:28.517Z DEBUG controllers.operator reconciling operator {"request": "/advanced-cluster-management.open-cluster-management"} 2021-02-03T08:18:28.521Z DEBUG controllers.operator reconciling operator {"request": "/ocs-operator.openshift-storage"} 2021-02-03T08:18:42.501Z DEBUG controllers.operator reconciling operator {"request": "/advanced-cluster-management.open-cluster-management"} 2021-02-03T08:18:42.592Z DEBUG controllers.operator reconciling operator {"request": "/advanced-cluster-management.open-cluster-management"} 2021-02-03T08:18:42.655Z DEBUG controllers.operator reconciling operator {"request": "/advanced-cluster-management.open-cluster-management"} 2021-02-03T08:18:42.765Z DEBUG controllers.operator reconciling operator {"request": "/advanced-cluster-management.open-cluster-management"} [root@preserve-olm-env bug1917537]# oc logs --since=300s olm-operator-7d65fc6994-vrpbb | grep -i debug | grep -i "reconciling operator" [root@preserve-olm-env bug1917537]# 4. Observe the CPU core usage of the OLM operator pod from the console. The cpu usage is back to normal after the operator installation is finished. 5. check the CSV for the operator [root@preserve-olm-env bug1917537]# oc get ip -n open-cluster-management NAME CSV APPROVAL APPROVED install-rrvl7 advanced-cluster-management.v2.1.2 Automatic true [root@preserve-olm-env bug1917537]# oc -n open-cluster-management get csv NAME DISPLAY VERSION REPLACES PHASE advanced-cluster-management.v2.1.2 Advanced Cluster Management for Kubernetes 2.1.2 advanced-cluster-management.v2.1.0 Succeeded [root@preserve-olm-env bug1917537]# oc get ip -n openshift-storage NAME CSV APPROVAL APPROVED install-fs2dc ocs-operator.v4.6.2 Automatic true [root@preserve-olm-env bug1917537]# oc -n openshift-storage get csv -w NAME DISPLAY VERSION REPLACES PHASE ocs-operator.v4.6.2 OpenShift Container Storage 4.6.2 Succeeded CPU usage snapshot for step 4 Observe the CPU core usage of the OLM operator pod from the console. https://user-images.githubusercontent.com/77608951/106724287-01902d00-6643-11eb-939e-c30bf6fba54b.png Since the problem described in this bug report should be resolved in a recent advisory, it has been closed with a resolution of ERRATA. For information on the advisory (Moderate: OpenShift Container Platform 4.7.0 security, bug fix, and enhancement update), and where to find the updated files, follow the link below. If the solution does not work for you, open a new bug report. https://access.redhat.com/errata/RHSA-2020:5633 |
{kind=link}
Description of problem: I can see continuous DEBUG "controllers.operator reconciling operator" messages in OLM operator logs on 4.6.8 production cluster which is running OLM 0.16.1 version. Version-Release number of selected component (if applicable): Version 0.16.1 How reproducible: Steps to Reproduce: 1. 2. 3. Actual results: Logs from OLM operator. --- ... 2021-01-18T16:10:43.091Z DEBUG controllers.operator reconciling operator {"request": "/prometheus.openshift-customer-monitoring"} 2021-01-18T16:10:43.130Z DEBUG controllers.operator reconciling operator {"request": "/cloud-ingress-operator.openshift-cloud-ingress-operator"} 2021-01-18T16:10:43.165Z DEBUG controllers.operator reconciling operator {"request": "/clowder.clowder"} 2021-01-18T16:10:43.295Z DEBUG controllers.operator reconciling operator {"request": "/prometheus.openshift-customer-monitoring"} 2021-01-18T16:10:43.295Z DEBUG controllers.operator reconciling operator {"request": "/clowder.clowder"} 2021-01-18T16:10:43.381Z DEBUG controllers.operator reconciling operator {"request": "/clowder.clowder"} 2021-01-18T16:10:43.511Z DEBUG controllers.operator reconciling operator {"request": "/cyndi.xjoin-stage"} 2021-01-18T16:10:43.524Z DEBUG controllers.operator reconciling operator {"request": "/clowder.clowder"} 2021-01-18T16:10:43.561Z DEBUG controllers.operator reconciling operator {"request": "/clowder.clowder"} 2021-01-18T16:10:43.792Z DEBUG controllers.operator reconciling operator {"request": "/amq-streams.amq-streams"} 2021-01-18T16:10:43.886Z DEBUG controllers.operator reconciling operator {"request": "/clowder.clowder"} ... time="2021-01-18T11:54:24Z" level=info msg="csv in operatorgroup" csv=prometheusoperator.0.37.0 id=cI/7w namespace=openshift-customer-monitoring opgroup=openshift-customer-monitoring phase=Succeeded time="2021-01-18T11:54:24Z" level=info msg="checking prometheusoperator.0.37.0" 2021-01-18T11:54:24.301Z ERROR controllers.operator Could not update Operator status {"request": "/clowder.clowder", "error": "Operation cannot be fulfilled on operators.operators.coreos.com \"clowder.clowder\": the object has been modified; please apply your changes to the latest version and try again"} github.com/go-logr/zapr.(*zapLogger).Error /build/vendor/github.com/go-logr/zapr/zapr.go:128 github.com/operator-framework/operator-lifecycle-manager/pkg/controller/operators.(*OperatorReconciler).Reconcile /build/pkg/controller/operators/operator_controller.go:163 sigs.k8s.io/controller-runtime/pkg/internal/controller.(*Controller).reconcileHandler /build/vendor/sigs.k8s.io/controller-runtime/pkg/internal/controller/controller.go:256 sigs.k8s.io/controller-runtime/pkg/internal/controller.(*Controller).processNextWorkItem /build/vendor/sigs.k8s.io/controller-runtime/pkg/internal/controller/controller.go:232 sigs.k8s.io/controller-runtime/pkg/internal/controller.(*Controller).worker /build/vendor/sigs.k8s.io/controller-runtime/pkg/internal/controller/controller.go:211 k8s.io/apimachinery/pkg/util/wait.BackoffUntil.func1 /build/vendor/k8s.io/apimachinery/pkg/util/wait/wait.go:155 k8s.io/apimachinery/pkg/util/wait.BackoffUntil /build/vendor/k8s.io/apimachinery/pkg/util/wait/wait.go:156 k8s.io/apimachinery/pkg/util/wait.JitterUntil /build/vendor/k8s.io/apimachinery/pkg/util/wait/wait.go:133 k8s.io/apimachinery/pkg/util/wait.Until /build/vendor/k8s.io/apimachinery/pkg/util/wait/wait.go:90 --- We suspect that due to this, ETCD is having high load of PUT requests which makes other core components of openshift unstable. Resulting in poor CPU and Memory performance of master nodes. --- $ oc get pods -A | grep openshift ... openshift-kube-apiserver kube-apiserver-ip-10-4-133-229.ec2.internal 5/5 Running 670 8d openshift-kube-apiserver kube-apiserver-ip-10-4-135-207.ec2.internal 5/5 Running 250 8d openshift-kube-apiserver kube-apiserver-ip-10-4-196-3.ec2.internal 5/5 Running 267 8d ... $ oc timeout 5m etcdctl watch / --prefix --write-out=fields 702 kubernetes.io/operators.coreos.com/operators/clowder.clowder" 436 kubernetes.io/operators.coreos.com/operators/container-security-operator.container-security-operator" 203 kubernetes.io/operators.coreos.com/clusterserviceversions/openshift-operator-lifecycle-manager 198 kubernetes.io/operators.coreos.com/clusterserviceversions/xjoin-stage 197 kubernetes.io/operators.coreos.com/clusterserviceversions/openshift-customer-monitoring 197 kubernetes.io/operators.coreos.com/clusterserviceversions/openshift-cloud-ingress-operator 187 kubernetes.io/operators.coreos.com/operators/amq-streams.amq-streams" 180 kubernetes.io/operators.coreos.com/clusterserviceversions/clowder 174 kubernetes.io/operators.coreos.com/clusterserviceversions/amq-streams 161 kubernetes.io/operators.coreos.com/operators/prometheus.openshift-customer-monitoring" --- Expected results: Additional info: