Bug 1936585
| Summary: | configure alerts if the catalogsources are missing | ||
|---|---|---|---|
| Product: | OpenShift Container Platform | Reporter: | Jatan Malde <jmalde> |
| Component: | OLM | Assignee: | Anik <anbhatta> |
| OLM sub component: | OperatorHub | QA Contact: | xzha |
| Status: | CLOSED ERRATA | Docs Contact: | |
| Severity: | medium | ||
| Priority: | medium | CC: | anbhatta, kuiwang, nhale |
| Version: | 4.6 | Keywords: | Reopened, Triaged |
| Target Milestone: | --- | ||
| Target Release: | 4.8.0 | ||
| Hardware: | x86_64 | ||
| OS: | All | ||
| Whiteboard: | |||
| Fixed In Version: | Doc Type: | Bug Fix | |
| Doc Text: |
Cause: Till OCP 4.5, the default catalogs deployed and managed by the marketplace-operator in the openshift-marketplace namespace were created by OperatorSources, the api expose by marketpalce-operator. Appropriate metrics/alerting were instrumented to indicate an error encountered by the OperatorSources. In OCP 4.6, OperatorSources were removed(after being deprecated for several previous releases) and the marketplace-operator directly created OLM's CatalogSource resource instead of OperatorSources. However, the same metrics/alerting instrumentation was not done for CatalogSources deployed in the openshift-marketplace namespace.
Consequence: Any errors encountered by these default CatalogSources were not highlighted using prometheus alerting.
Fix: A new metric `catalogsource_ready` was introduced in olm (https://github.com/operator-framework/operator-lifecycle-manager/pull/2152), which is then used by the marketplace-operator to fire alerts whenever the metric for a default CatalogSource indicated that a CatalogSource is in an unready state.
Result: Prometheus alerts for unready default CatalogSource in the openshift-marketplace namespace (https://github.com/operator-framework/operator-marketplace/pull/402#issue-647984868)
|
Story Points: | --- |
| Clone Of: | Environment: | ||
| Last Closed: | 2021-07-27 22:51:42 UTC | Type: | Bug |
| Regression: | --- | Mount Type: | --- |
| Documentation: | --- | CRM: | |
| Verified Versions: | Category: | --- | |
| oVirt Team: | --- | RHEL 7.3 requirements from Atomic Host: | |
| Cloudforms Team: | --- | Target Upstream Version: | |
| Embargoed: | |||
| Bug Depends On: | 1961320 | ||
| Bug Blocks: | |||
|
Description
Jatan Malde
2021-03-08 19:21:32 UTC
Jatan,
> Checking the catalog sources pods, we do see errors from the proxy while connecting to the mentioned sources in the catalogsource but there is no alert with this reported mentioning the requirement of pod restart post the network issue getting resolved.
In 4.6, the "marketplace" catalogs included in OpenShift were switched from being sourced from AppRegistry, to being sourced from a data store baked into the catalog images themselves. This means that the catalog pods don't make any external requests at runtime, so the issue doesn't seem to make much sense as described.
That being said, I'm going to close this out. If you feel there's been a misunderstanding, please re-open this BZ with reproduction steps, expected, and actual results on a 4.6+ cluster.
Thanks!
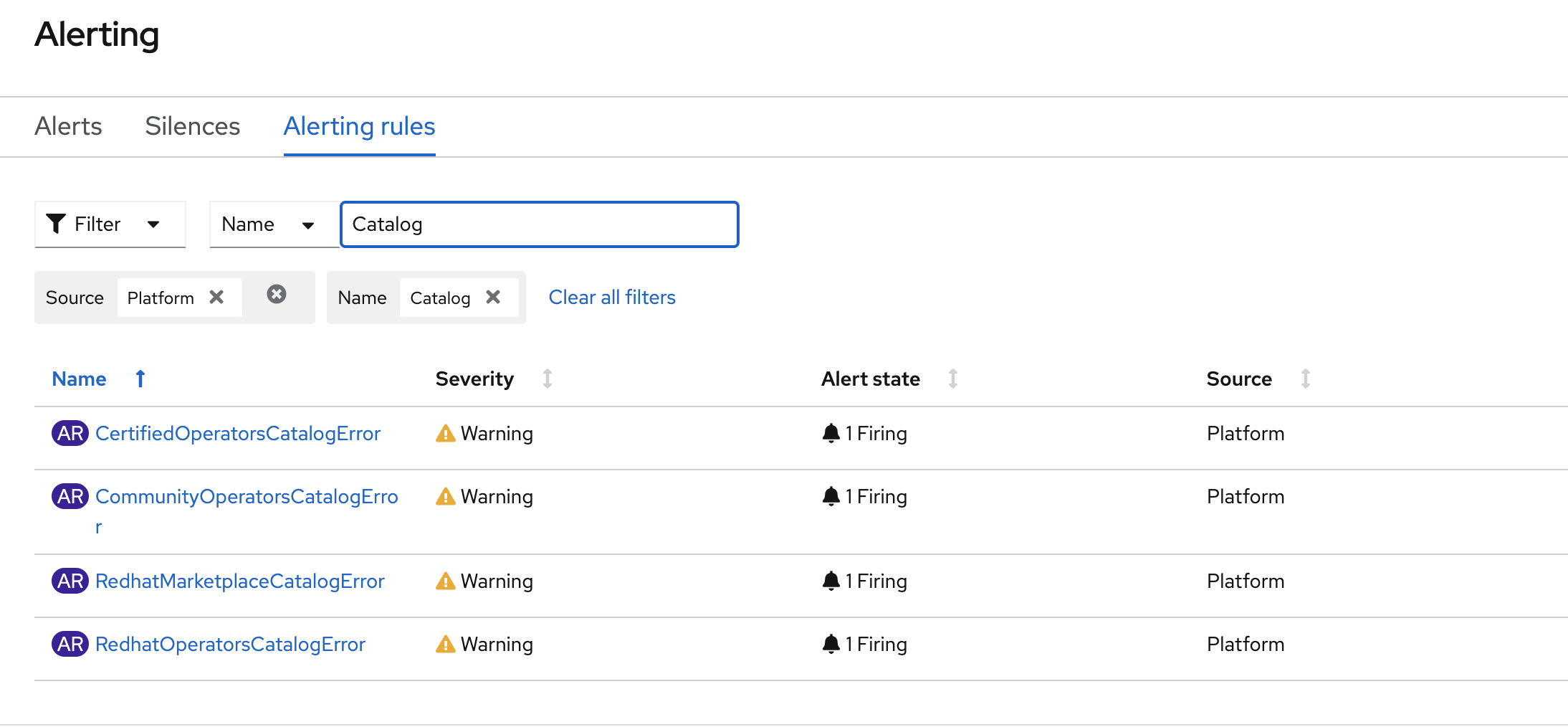
verify: zhaoxia@xzha-mac bug-1945548 % oc get clusterversion NAME VERSION AVAILABLE PROGRESSING SINCE STATUS version 4.8.0-0.nightly-2021-05-27-030333 True False 62m Cluster version is 4.8.0-0.nightly-2021-05-27-030333 1, mark all worker nodes as unschedulable zhaoxia@xzha-mac bug-1945548 % oc get nodes NAME STATUS ROLES AGE VERSION ci-ln-dfls75b-f76d1-lp7sf-master-0 Ready master 55m v1.21.0-rc.0+bb94839 ci-ln-dfls75b-f76d1-lp7sf-master-1 Ready master 55m v1.21.0-rc.0+bb94839 ci-ln-dfls75b-f76d1-lp7sf-master-2 Ready master 55m v1.21.0-rc.0+bb94839 ci-ln-dfls75b-f76d1-lp7sf-worker-b-j2q5q Ready worker 47m v1.21.0-rc.0+bb94839 ci-ln-dfls75b-f76d1-lp7sf-worker-c-pv2n7 Ready worker 44m v1.21.0-rc.0+bb94839 ci-ln-dfls75b-f76d1-lp7sf-worker-d-llvnf Ready worker 44m v1.21.0-rc.0+bb94839 zhaoxia@xzha-mac bug-1945548 % oc adm cordon ci-ln-dfls75b-f76d1-lp7sf-worker-b-j2q5q ci-ln-dfls75b-f76d1-lp7sf-worker-c-pv2n7 ci-ln-dfls75b-f76d1-lp7sf-worker-d-llvnf 2, delete pod certified-operators and community-operators zhaoxia@xzha-mac bug-1945548 % oc delete pod certified-operators-88s99 pod "certified-operators-88s99" deleted zhaoxia@xzha-mac bug-1945548 % oc delete pod community-operators-wtzdp pod "community-operators-wtzdp" deleted 3, check pod status zhaoxia@xzha-mac bug-1945548 % oc get pod NAME READY STATUS RESTARTS AGE certified-operators-cplq7 0/1 Pending 0 26m certified-operators-t84zp 0/1 Pending 0 29m community-operators-nm2hp 0/1 Pending 0 21m community-operators-rmwbs 0/1 Pending 0 29m marketplace-operator-64586f9897-bcbwm 1/1 Running 0 88m redhat-marketplace-dffn8 1/1 Running 0 86m redhat-marketplace-qhmmc 0/1 Pending 0 21m redhat-operators-qn8mw 0/1 Pending 0 30m redhat-operators-smmlq 1/1 Running 0 32m 4. check Metics and alert Metics: https://user-images.githubusercontent.com/77608951/119802706-5d900180-bf11-11eb-948e-c1e719c4c8b6.png https://user-images.githubusercontent.com/77608951/119802877-857f6500-bf11-11eb-9cb5-2420e7e1cbc7.png there is no alert CommunityOperatorsCatalogError and CertifiedOperatorsCatalogError and there is alert rule CommunityOperatorsCatalogError and CertifiedOperatorsCatalogError https://user-images.githubusercontent.com/77608951/119803283-e313b180-bf11-11eb-8af3-f8eb442fb437.png https://user-images.githubusercontent.com/77608951/119803550-240bc600-bf12-11eb-9fc3-6363322a260a.png verify failed. Verify [root@preserve-olm-agent-test ~]# oc get clusterversion NAME VERSION AVAILABLE PROGRESSING SINCE STATUS version 4.8.0-0.nightly-2021-05-29-114625 True False 10m Cluster version is 4.8.0-0.nightly-2021-05-29-114625 1, mark all worker nodes as unschedulable [root@preserve-olm-agent-test ~]# oc get nodes NAME STATUS ROLES AGE VERSION ip-10-0-133-33.us-east-2.compute.internal Ready worker 33m v1.21.0-rc.0+4b2b6ff ip-10-0-148-42.us-east-2.compute.internal Ready master 36m v1.21.0-rc.0+4b2b6ff ip-10-0-172-186.us-east-2.compute.internal Ready worker 32m v1.21.0-rc.0+4b2b6ff ip-10-0-177-55.us-east-2.compute.internal Ready master 36m v1.21.0-rc.0+4b2b6ff ip-10-0-196-44.us-east-2.compute.internal Ready master 40m v1.21.0-rc.0+4b2b6ff ip-10-0-202-160.us-east-2.compute.internal Ready worker 33m v1.21.0-rc.0+4b2b6ff [root@preserve-olm-agent-test ~]# oc adm cordon ip-10-0-133-33.us-east-2.compute.internal ip-10-0-172-186.us-east-2.compute.internal ip-10-0-202-160.us-east-2.compute.internal node/ip-10-0-133-33.us-east-2.compute.internal cordoned node/ip-10-0-172-186.us-east-2.compute.internal cordoned node/ip-10-0-202-160.us-east-2.compute.internal cordoned [root@preserve-olm-agent-test ~]# oc get nodes NAME STATUS ROLES AGE VERSION ip-10-0-133-33.us-east-2.compute.internal Ready,SchedulingDisabled worker 34m v1.21.0-rc.0+4b2b6ff ip-10-0-148-42.us-east-2.compute.internal Ready master 37m v1.21.0-rc.0+4b2b6ff ip-10-0-172-186.us-east-2.compute.internal Ready,SchedulingDisabled worker 33m v1.21.0-rc.0+4b2b6ff ip-10-0-177-55.us-east-2.compute.internal Ready master 37m v1.21.0-rc.0+4b2b6ff ip-10-0-196-44.us-east-2.compute.internal Ready master 41m v1.21.0-rc.0+4b2b6ff ip-10-0-202-160.us-east-2.compute.internal Ready,SchedulingDisabled worker 33m v1.21.0-rc.0+4b2b6ff 2. delete pod redhat-operators and community-operators [root@preserve-olm-agent-test ~]# oc get pod NAME READY STATUS RESTARTS AGE a044a04a2dc6f2e2698bbf09dcbb0874c8f72e00cd06b114c381d0437bnmzjx 0/1 Completed 0 9m12s cd41f97077889e6ec45c6e342d9e32c7296fefc73c482440a60cfa4e48jwhwh 0/1 Completed 0 9m12s certified-operators-vg7hk 1/1 Running 0 11m community-operators-6nc2q 1/1 Running 0 11m marketplace-operator-745fbf4bfd-hc4b6 1/1 Running 0 11m qe-app-registry-rb5ps 1/1 Running 0 9m redhat-marketplace-bj4n8 1/1 Running 0 11m redhat-operators-fktt9 1/1 Running 0 11m [root@preserve-olm-agent-test ~]# oc delete pod community-operators-6nc2q pod "community-operators-6nc2q" deleted [root@preserve-olm-agent-test ~]# oc delete pod redhat-operators-fktt9 pod "redhat-operators-fktt9" deleted 3, check Metics and alert https://user-images.githubusercontent.com/77608951/120154328-596e2780-c222-11eb-9474-b3078a4d6e51.png https://user-images.githubusercontent.com/77608951/120156670-c8e51680-c224-11eb-8ef8-2f8bf6ba70e5.png https://user-images.githubusercontent.com/77608951/120156800-eb772f80-c224-11eb-9cb5-89c1ffbeb5a5.png alerts CommunityOperatorsCatalogError CertifiedOperatorsCatalogError RedhatOperatorsCatalogError RedhatMarketplaceCatalogError happed. LGTM, verified. Since the problem described in this bug report should be resolved in a recent advisory, it has been closed with a resolution of ERRATA. For information on the advisory (Moderate: OpenShift Container Platform 4.8.2 bug fix and security update), and where to find the updated files, follow the link below. If the solution does not work for you, open a new bug report. https://access.redhat.com/errata/RHSA-2021:2438 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}